Summary: Efforts to improve scientific integrity must grapple with both questionable research practices that fall within the current "rules of the game" and outright misconduct. Survey and audit data suggest disturbing lower bounds for misconduct, and suggest the possibility of rates high enough to meaningfully distort readings of the scientific literature. The problem could be worse for "null fields" studying nonexistent effects, and for studies that seemingly have top methodological standards. I discuss this analysis in the context of cold fusion and parapsychology, commonly thought to be null fields. These fields may be more at risk of fraud than others, but may also provide a warning about the potential for misconduct in more conventional domains.
Questionable research practices vs fraud
Meta-research studies have documented a number of different issues impairing scientific credibility that are within the standard "rules of the game," biasing results without direct falsification or fabrication of data:
 Since QRPs are very common, can easily produce false positives, and may be practiced without outright lies, they have been the focus of much of the attentions of reformers. Simmons, Nelson, and Simonsohn (2012) offer a "21 word solution," requiring authors to state:
Since QRPs are very common, can easily produce false positives, and may be practiced without outright lies, they have been the focus of much of the attentions of reformers. Simmons, Nelson, and Simonsohn (2012) offer a "21 word solution," requiring authors to state:
Another technique, "p-curve" analysis, looks at the distribution of published results passing the p=0.05 significance test, asking whether p-values are evenly distributed above that threshold (suggesting p-hacking) or concentrated at more extreme values (suggesting an effect other than simple publication bias). Again, frauds falsifying data can falsify to whatever p-value they prefer.
In aggregate, reductions in QRPs could make misleading fraudulent results stand out more, since they could no longer hide amongst a forest of merely p-hacked results, and some measures directly complicate fraud, like data sharing (many cases of fraud exposure come from re-analysis of raw data). But addressing the combination of QRPs and fraud, especially in understanding existing literature, does complicate the picture.
How common is fraud?
If the base rate of fraud is sufficiently low, it might be mostly negligible, especially for results publicly replicated by multiple independent groups (rare as that is). There have been a number of attempts to estimate the frequency of fradulent practices in science. Fanneli (2009) offers us "How Many Scientists Fabricate and Falsify Research? A Systematic Review and Meta-Analysis of Survey Data".
One would expect social desirability bias and fear of punishment to suppress admission rates dramatically, so I would expect the survey results are a substantial underestimate. Theoretically, they could be an overestimate, due to response bias, or a small minority of false confessions along the lines of people who report their religion as Jedi or agree that lizard men rule the United States.
In John et al. (2012) in addition to confession data, psychologists were asked to estimate rates of QRPs and fraud among their peers, as well as to estimate the portion of the guilty who woudl confess. This table shows the estimated prevalence rates from 1) confession; 2) peer estimates of frequency 3) the combination of empirical confession rates with peer estimates of the portion of the guilty who would confess. For falsification of data, the latter are much higher, around 10% and 40%, with a geometric mean of the three estimation procedures at 9%.

For poll estimates near the extremes of the scale, the mean can be heavily influenced by a few outliers, so I asked John for the median data (with and without the "Bayesian truth serum" technique):
So median psychologist respondent estimates a quite substantial fraud rate, several times higher than the anonymous admission rate, and tremendously higher than the rate of exposure.
There are also fraud data based on audits of samples of research. Faaneli (2009):
How is fraud distributed across fields, types of research, and publication status?
The above overall estimates of the frequency of fraud and fraudsters are troubling, but they need not be evenly distributed. If some areas of research disproportionately attract or retain fraudsters, then the local rates may be even worse.
One selective pressure is the demand for success and positive results. Fraudsters can ensure that their experiments always appear to 'work', and publish more papers with positive significant results. If they can publish all their experiments, fraudsters may make up a larger share of the published literature than their share of the researcher population. Likewise, if hiring and tenure are based on publication record, this would favor fraudsters being over-represented among those graduate students who are able to obtain academic jobs, professors who achieve tenure, and researchers at elite institutions.
Fields and types of research also vary in the feasibility of non-fraudulent work to advance a career. Consider the following routes to producing publications and getting continued funding for career and research:
Parapsychology: control group for science
Parapsychology, which tries to show that psychic powers exist, usually through randomized experiments, has been called a control group for science, I believe originally by Michael Vassar (in the lineage of this post). There are many reasons to think it is a null field, including:
Nonetheless, parapsychologists are able to produce a published research literature with an excess of positive results and meta-analyses with enormous p-values which they claim show that psychic powers exist after all.
My sense is that the bulk of parapsychology results are the result of p-hacking, publication biases, and reporting biases. Often experiments have odd sample sizes, report results for strange subgroups, or emphasize a significant but unusual analysis without mentioning more standard main effect analyses (which do not show a result). Outright fraudsters don't need to resort to such tactics to generate results.
Following the controversy over tenured psychologist Daryl Bem (who has no direct financial motive to generate positive psi results), his experiments seem p-hacked and subject to QRPs but not fraudulent. As discussed in an earlier post, the published experiments used nonstandard analyses without sufficient correction for multiple comparisons, excluded some previously presented data, got significant results more often than would be predicted even if the effects were given the low power, and other signs of p-hacking.
However, there are individual parapsychology experiments that purport to have rather high quality methodology, and report very impressive effects with somewhat reasonable sample sizes. For example, consider the "ganzfeld" experiments, which supposedly involve one participant being presented with 1 of 4 stimuli at random and telepathically transmitting its identity to someone in another room. That second participant then discusses his or her imaginations about the target with the experimenter (who is supposed to be blinded as to the target), with that discussion converted into a guess as to the stimulus.
Early versions of the procedure varied in their analysis in accord with p-hacking, and early meta-analysis also seems somewhat p-hacked (the subset of procedures chosen for meta-analysis had higher success rates). Nonetheless, after discussion with skeptics, the procedure was mostly stabilized in a Joint Communique involving a skeptical psychologist (Ray Hyman) and a parapsychologist (Charles Honorton, head of the Psychophysical Research Laboratories or PRL). Honorton's lab undertook a series of experiments purportedly following this protocol, with many but not all experimenter steps automated (so the experiments were know as "autoganzfeld").
Given this setup there is a clear null hypothesis of 25% accuracy, and little freedom to change the analysis. The main options I can see for getting positive results in the absence of psychic powers are:
The first four possibilities rely on failure to publish trials, and are most severe for small studies (and indeed most ganzfeld studies, like most parapsychology studies are underpowered). For experimenters who claim to have published all of the trials they conducted, and to have conducted a large sample of trials, the last two are the most plausible (hidden trials would be an instance of fraud in such a case), along with "other." And there are at least a few such experiments.
For example a recent ganzfeld meta-analysis includes one study with 60/128 hits. If each trial had an independent probability of success of 25%, this would be around a 1 in 14 million event. Another claims 57/138, close to 1 in 50,000. The possibility of optional stopping reduces this somewhat, but nonetheless such experiments should not yet have happened absent systematic error, cheating, or psychic powers. Honorton's lab's ganzfeld experiments post-Communique were supposedly published in full with no omitted trials and a hit rate of 119/354, a hit rate which should happen less than 1 in 5,000 times given a random 25% true accuracy.
Sensory leakage seems a bit wild, but is often hard to rule out (e.g. Honorton's PRL laboratory was shut down, making it hard to test the quality of soundproofing) and there are mechanisms that could allow it in various cases. There is certainly a history of bogus parapsychology results caused by sensory leakage, such as card guessing experiments where subjects could see the cards or markings on them. Also, there is a selection effect: if an apparatus and experimental setup turn out to "work" then they will be used again and again to produce apparently enormous results, while failed experimental setups will be frequently changed. Sensory leakage could be quite conclusively ruled out in a sufficiently vetted physical setup examined by independent quality auditors.
Fraud is naturally an unpleasant suggestion, for both the innocent and the guilty. The usual rebuttal to this possibility is that fraudsters must be too rare to matter much. But the surveys and audit estimates of fraud rates above suggest the baseline is not very rare. If 5% or 10% of psychologists in general have committed fraud, parapsychologists are disproportionately selected for fraud, and we restrict ourselves to experiments with low analysis freedom and large sample sizes (where p-hacking is hard) we might quickly reach quite high rates.
Now, there is uncertainty about how high baseline fraud rates are, about selection for frauds by field, and selection for fraud by experiment type in null fields. These are testable empirical hypotheses, and parapsychologists I have spoken to have argued that in fact parapsychologists are much more honest and rigorous in their methods than conventional scientists. But I think the hypothesis of high fraud rates when we zoom into the relevant area deserves nontrivial credence, before updating on the evidence for parapsychology being a null field. So to convince me that parpasychology is right I would need strong evidence against the fraud hypothesis, like repeated large highly scrutinized replications by independent skeptical researchers, evidence sufficient to make a high fraud rate (or other systematic error) more incredible than psychic powers.
Are parapsychologists more or less at risk for fraud than regular scientists?
If parapsychologists are much more strongly selected for or encouraged to commit fraud than scientists in other disciplines, than we might believe that fraud is a major problem for the most robust-seeming results in parapsychology, but not in other fields. But if the risk levels are not too far apart, then this may support a new angle for scrutinizing other academic fields.
I have encountered a number of arguments from parapsychologists that they are more trustworthy than other scientists, including:
Questionable research practices vs fraud
Meta-research studies have documented a number of different issues impairing scientific credibility that are within the standard "rules of the game," biasing results without direct falsification or fabrication of data:
- P-hacking: making choices in analysis of the data that produce a more significant result, after seeing the data so that bias can subtly or intentionally exaggerate effects; p-hacking using a handful of common analytical choices can reliably produce significance below the p=0.05 threshold
- Asymmetric error correction: when recording errors or methodological problems skew a result against a researcher's hypothesis, or a significant result these are corrected more often than errors that bolster the hypothesis
- Publication bias: researchers are more likely to write up and submit for publication positive results or results that favor their hypotheses, and journals are more likely to accept sexy positive results
- Failure to share data and code: even when this is supposedly required by journals or governments, compliance rates are abysmal and those who fail to share data on average have weaker evidence and lower quality reporting of statistical results
- Exact replications are rare
- Optional stopping: selectively stopping data collection more often when interim results are positive, which increases the rate of statistical significance by concentrating positive and negative trials in separate studies, amplifying the effect of publication and analytical biases

“We report how we determined our sample size, all data exclusions (if any), all manipulations, and all measures in the study.”The idea is to convert QRPs, which researchers may commit while thinking of themselves as basically honest, into outright fraud. The thought is that most researchers will shy away from outright misconduct both out of personal integrity and fear of academic misconduct charges. Of course, the marginal deterrence will be much less for researchers who were already engaged in fraud: if one is already making up data, why not claim good methodology too?
Another technique, "p-curve" analysis, looks at the distribution of published results passing the p=0.05 significance test, asking whether p-values are evenly distributed above that threshold (suggesting p-hacking) or concentrated at more extreme values (suggesting an effect other than simple publication bias). Again, frauds falsifying data can falsify to whatever p-value they prefer.
In aggregate, reductions in QRPs could make misleading fraudulent results stand out more, since they could no longer hide amongst a forest of merely p-hacked results, and some measures directly complicate fraud, like data sharing (many cases of fraud exposure come from re-analysis of raw data). But addressing the combination of QRPs and fraud, especially in understanding existing literature, does complicate the picture.
How common is fraud?
If the base rate of fraud is sufficiently low, it might be mostly negligible, especially for results publicly replicated by multiple independent groups (rare as that is). There have been a number of attempts to estimate the frequency of fradulent practices in science. Fanneli (2009) offers us "How Many Scientists Fabricate and Falsify Research? A Systematic Review and Meta-Analysis of Survey Data".
To standardize outcomes, the number of respondents who recalled at least one incident of misconduct was calculated for each question, and the analysis was limited to behaviours that distort scientific knowledge: fabrication, falsification, “cooking” of data, etc… Survey questions on plagiarism and other forms of professional misconduct were excluded. The final sample consisted of 21 surveys that were included in the systematic review, and 18 in the meta-analysis.
A pooled weighted average of 1.97% (N = 7, 95%CI: 0.86–4.45) of scientists admitted to have fabricated, falsified or modified data or results at least once –a serious form of misconduct by any standard– and up to 33.7% admitted other questionable research practices. In surveys asking about the behaviour of colleagues, admission rates were 14.12% (N = 12, 95% CI: 9.91–19.72) for falsification, and up to 72% for other questionable research practices. Meta-regression showed that self reports surveys, surveys using the words “falsification” or “fabrication”, and mailed surveys yielded lower percentages of misconduct. When these factors were controlled for, misconduct was reported more frequently by medical/pharmacological researchers than others.
Considering that these surveys ask sensitive questions and have other limitations, it appears likely that this is a conservative estimate of the true prevalence of scientific misconduct.
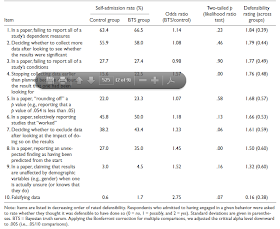
In John et al. (2012) in addition to confession data, psychologists were asked to estimate rates of QRPs and fraud among their peers, as well as to estimate the portion of the guilty who woudl confess. This table shows the estimated prevalence rates from 1) confession; 2) peer estimates of frequency 3) the combination of empirical confession rates with peer estimates of the portion of the guilty who would confess. For falsification of data, the latter are much higher, around 10% and 40%, with a geometric mean of the three estimation procedures at 9%.

For poll estimates near the extremes of the scale, the mean can be heavily influenced by a few outliers, so I asked John for the median data (with and without the "Bayesian truth serum" technique):
Item control median bts median In a paper, failing to report all of a study's dependent measures - The percentage of research psychologists who have engaged in this practice 62 70 Deciding whether to collect more data after looking to see whether the results were significant - The percentage of research psychologists who have engaged in this practice 68 70 In a paper, failing to report all of a study’s conditions - The percentage of research psychologists who have engaged in this practice 29 30 Stopping collecting data earlier than planned because one found the result that one had been looking for - The percentage of research psychologists who have engaged in this practice 31 37 In a paper, “rounding off” a p value (e.g., reporting that a p value of .054 is less than .05) - The percentage of research psychologists who have engaged in this practice 33.5 31 In a paper, selectively reporting studies that “worked” - The percentage of research psychologists who have engaged in this practice 63 70 Deciding whether to exclude data after looking at the impact of doing so on the results - The percentage of research psychologists who have engaged in this practice 42 40 In a paper, reporting an unexpected finding as having been predicted from the start - The percentage of research psychologists who have engaged in this practice 50 50 In a paper, claiming that results are unaffected by demographic variables (e.g., gender) when one is actually unsure (or knows that they do) - The percentage of research psychologists who have engaged in this practice 10 15 Falsifying data - The percentage of research psychologists who have engaged in this practice 5 6
So median psychologist respondent estimates a quite substantial fraud rate, several times higher than the anonymous admission rate, and tremendously higher than the rate of exposure.
There are also fraud data based on audits of samples of research. Faaneli (2009):
To measure the frequency of misconduct, different approaches have been employed, and they have produced a corresponding variety of estimates. Based on the number of government confirmed cases in the US, fraud is documented in about 1 every 100.000 scientists [11], or 1 every 10.000 according to a different counting [3]. Paper retractions from the PubMed library due to misconduct, on the other hand, have a frequency of 0.02%, which led to speculation that between 0.02 and 0.2% of papers in the literature are fraudulent [17]. Eight out of 800 papers submitted to The Journal of Cell Biology had digital images that had been improperly manipulated, suggesting a 1% frequency [11]. Finally, routine data audits conducted by the US Food and Drug Administration between 1977 and 1990 found deficiencies and flaws in 10–20% of studies, and led to 2% of clinical investigators being judged guilty of serious scientific misconduct [18].The audit estimates should be considered rough lower bounds, excluding successful and clever fraud, or fraud on different dimensions of the experiments (each of these measures could only catch a particular subset of fraud).
How is fraud distributed across fields, types of research, and publication status?
The above overall estimates of the frequency of fraud and fraudsters are troubling, but they need not be evenly distributed. If some areas of research disproportionately attract or retain fraudsters, then the local rates may be even worse.
One selective pressure is the demand for success and positive results. Fraudsters can ensure that their experiments always appear to 'work', and publish more papers with positive significant results. If they can publish all their experiments, fraudsters may make up a larger share of the published literature than their share of the researcher population. Likewise, if hiring and tenure are based on publication record, this would favor fraudsters being over-represented among those graduate students who are able to obtain academic jobs, professors who achieve tenure, and researchers at elite institutions.
Fields and types of research also vary in the feasibility of non-fraudulent work to advance a career. Consider the following routes to producing publications and getting continued funding for career and research:
- Fail to generate significant results and wash out of the field, unable to acquire positions or funding
- Perform experiments on real effects, generating significant positive results (although this will usually not happen without p-hacking when using the underpowered studies typical of many fields)
- Peform experiments looking for imaginary effects, generating results using p-hacking and other QRPs short of blatant fraud
- Conduct meta-analysis or theoretical commentary on existing experiments (which may be p-hacked and fraudulent)
- Act as one member of a team with other scientists working on imaginary effects, where others in the team use fraud or QRPs to create significance
- Conduct fraud oneself
In a wonderful essay, Cosma Shalizi discusses the Neutral Model of Inquiry, imagining fields such as evidence-based haruspicy where the null hypothesis is always true and considering the distribution of results that would be produced by publication and reporting biases. Call these "null fields." In a null field researchers running rigorous experiments will have no hope of regularly producing results and advancing their careers, and will tend to depart the field. Those who remain in the field will have to disproportionately rely on the other routes to results, p-hacking, fraud, or commentary and other contributions that rely on the p-hackers and frauds.
If we restrict our attention to experiments in the null field with good pre-registered planned methodology, large sample sizes, and other defenses against p-hacking and systematic error, then we would expect an even higher rate of fraud: only fraudsters will be able to produce results regularly under these conditions (by falsification of data, or lying about the methodology). If such experiments make up a small portion of the field, with most pursuing p-hacking strategies, then the 'rigorous methods' portion might have fraud rates several times as high.
The case of cold fusion
For concreteness, consider the case of cold fusion. In 1989 Pons and Fleischmann claimed to have been able to generate heat from nuclear fusion at room temperature using palladium, despite the Coulomb barrier. This created immense excitement, with many scientists attempting to replicate the findings, but not finding results. Those few who claimed to have had done so were unable to repeat or demonstrate the effect (e.g. with proper radiation detectors, isotope tests, etc) and the subject largely died down. However, a few hundred people have subsequently puttered with cold fusion experiments for decades, reporting fluctuating and inconsistent results suggestive of p-hacking and publication bias without any rigorous demonstrations (although such demonstrations ought to be achievable if the effect is real).
If we zoom in on the most impressive reports there is an elevation in indications of systematic experimental error and fraud, relative to p-hacking. Reports of mysteriously produced elements (without radiation and other features of fusion) have been traced to experimental contamination. Claimed working cold fusion devices mysteriously avoid rigorous testing before fading away, and proponents are enriched with individuals with a history of running off with investor money for multiple scientifically implausible energy technologies without delivering.
I would guess that most of cold fusion research community is engaged in pathological science honestly pursuing effects they believe exist with p-hacking and bias but not intentional fraud. The researchers in the field are those who remain after the exodus of a vast quantity of scientists, and so are enriched for poor practices, as well as unlucky individuals who got mild statistical flukes in early experiments and are working to recapture them. But when someone purports to be able to generate meaningful excess heat or rock-solid proof (isotopes, radiation, etc) I expect outright fraud with high confidence.
To overcome that view I would need strong additional evidence, like reliable replication or demonstrations by independent scientists, commercial deployment or the like.
If we restrict our attention to experiments in the null field with good pre-registered planned methodology, large sample sizes, and other defenses against p-hacking and systematic error, then we would expect an even higher rate of fraud: only fraudsters will be able to produce results regularly under these conditions (by falsification of data, or lying about the methodology). If such experiments make up a small portion of the field, with most pursuing p-hacking strategies, then the 'rigorous methods' portion might have fraud rates several times as high.
The case of cold fusion
For concreteness, consider the case of cold fusion. In 1989 Pons and Fleischmann claimed to have been able to generate heat from nuclear fusion at room temperature using palladium, despite the Coulomb barrier. This created immense excitement, with many scientists attempting to replicate the findings, but not finding results. Those few who claimed to have had done so were unable to repeat or demonstrate the effect (e.g. with proper radiation detectors, isotope tests, etc) and the subject largely died down. However, a few hundred people have subsequently puttered with cold fusion experiments for decades, reporting fluctuating and inconsistent results suggestive of p-hacking and publication bias without any rigorous demonstrations (although such demonstrations ought to be achievable if the effect is real).
If we zoom in on the most impressive reports there is an elevation in indications of systematic experimental error and fraud, relative to p-hacking. Reports of mysteriously produced elements (without radiation and other features of fusion) have been traced to experimental contamination. Claimed working cold fusion devices mysteriously avoid rigorous testing before fading away, and proponents are enriched with individuals with a history of running off with investor money for multiple scientifically implausible energy technologies without delivering.
I would guess that most of cold fusion research community is engaged in pathological science honestly pursuing effects they believe exist with p-hacking and bias but not intentional fraud. The researchers in the field are those who remain after the exodus of a vast quantity of scientists, and so are enriched for poor practices, as well as unlucky individuals who got mild statistical flukes in early experiments and are working to recapture them. But when someone purports to be able to generate meaningful excess heat or rock-solid proof (isotopes, radiation, etc) I expect outright fraud with high confidence.
To overcome that view I would need strong additional evidence, like reliable replication or demonstrations by independent scientists, commercial deployment or the like.
Parapsychology: control group for science
Parapsychology, which tries to show that psychic powers exist, usually through randomized experiments, has been called a control group for science, I believe originally by Michael Vassar (in the lineage of this post). There are many reasons to think it is a null field, including:
- Physics as we know it does not provide a mechanism for psychic powers, as ideas like radio transmitters in the brain have been falsified
- The lack of any visible or unambiguous manifestations, such as applying even tiny telekinetic force to an isolated microbalance, transmitting sentences with information content of dozens of bits, imbalanced casino payouts, or the use of psychic powers to predict the stock market (making billions, or just cumulative public short-term advance predictions)
- The failure of parapsychology to set up a high-power rigorous experimental protocol that independent scientists can use to reliably confirm psychic powers, after a century of trying
- The psychological mechanisms and known fraudulent practices that inspire belief in psychic powers among the general population provide an explanation for the continued pursuit of parapsychology and biased work even in the absence of real psychic powers
Nonetheless, parapsychologists are able to produce a published research literature with an excess of positive results and meta-analyses with enormous p-values which they claim show that psychic powers exist after all.
My sense is that the bulk of parapsychology results are the result of p-hacking, publication biases, and reporting biases. Often experiments have odd sample sizes, report results for strange subgroups, or emphasize a significant but unusual analysis without mentioning more standard main effect analyses (which do not show a result). Outright fraudsters don't need to resort to such tactics to generate results.
Following the controversy over tenured psychologist Daryl Bem (who has no direct financial motive to generate positive psi results), his experiments seem p-hacked and subject to QRPs but not fraudulent. As discussed in an earlier post, the published experiments used nonstandard analyses without sufficient correction for multiple comparisons, excluded some previously presented data, got significant results more often than would be predicted even if the effects were given the low power, and other signs of p-hacking.
However, there are individual parapsychology experiments that purport to have rather high quality methodology, and report very impressive effects with somewhat reasonable sample sizes. For example, consider the "ganzfeld" experiments, which supposedly involve one participant being presented with 1 of 4 stimuli at random and telepathically transmitting its identity to someone in another room. That second participant then discusses his or her imaginations about the target with the experimenter (who is supposed to be blinded as to the target), with that discussion converted into a guess as to the stimulus.
Early versions of the procedure varied in their analysis in accord with p-hacking, and early meta-analysis also seems somewhat p-hacked (the subset of procedures chosen for meta-analysis had higher success rates). Nonetheless, after discussion with skeptics, the procedure was mostly stabilized in a Joint Communique involving a skeptical psychologist (Ray Hyman) and a parapsychologist (Charles Honorton, head of the Psychophysical Research Laboratories or PRL). Honorton's lab undertook a series of experiments purportedly following this protocol, with many but not all experimenter steps automated (so the experiments were know as "autoganzfeld").
Given this setup there is a clear null hypothesis of 25% accuracy, and little freedom to change the analysis. The main options I can see for getting positive results in the absence of psychic powers are:
- Optional starting, run 'test trials to calibrate the setup' and include them in the formal study more often when they are positive
- Optional stopping, to concentrate positive and negative trials in separate 'studies', and then differentially publish the positive ones
- Conduct many trials while collecting various demographic data (is the person an artist, a meditator, a psi believer, female, open to experience, reporting history of psi?), then lump the data into "studies" by p-hacking that demographic data, and differentially publish the positive studies
- Publication bias of whole studies (not enough on its own without interaction with other QRPs to concentrate positive results in some studies, but the combined effect can be large)
- Sensory leakage, whereby the stimulus is actually detectable by the guesser; e.g. inadequate soundproofing, failure of blinding, fingerprints on the correct object to be picked (when shown to the guesser), VCR displays reflecting the wear on the VCR tape from showing the target stimulus for an hour to the 'sender' so that it looked visually different than the non-target stimuli when the tape was shown to 'receivers'
- Fraud
The first four possibilities rely on failure to publish trials, and are most severe for small studies (and indeed most ganzfeld studies, like most parapsychology studies are underpowered). For experimenters who claim to have published all of the trials they conducted, and to have conducted a large sample of trials, the last two are the most plausible (hidden trials would be an instance of fraud in such a case), along with "other." And there are at least a few such experiments.
For example a recent ganzfeld meta-analysis includes one study with 60/128 hits. If each trial had an independent probability of success of 25%, this would be around a 1 in 14 million event. Another claims 57/138, close to 1 in 50,000. The possibility of optional stopping reduces this somewhat, but nonetheless such experiments should not yet have happened absent systematic error, cheating, or psychic powers. Honorton's lab's ganzfeld experiments post-Communique were supposedly published in full with no omitted trials and a hit rate of 119/354, a hit rate which should happen less than 1 in 5,000 times given a random 25% true accuracy.
Sensory leakage seems a bit wild, but is often hard to rule out (e.g. Honorton's PRL laboratory was shut down, making it hard to test the quality of soundproofing) and there are mechanisms that could allow it in various cases. There is certainly a history of bogus parapsychology results caused by sensory leakage, such as card guessing experiments where subjects could see the cards or markings on them. Also, there is a selection effect: if an apparatus and experimental setup turn out to "work" then they will be used again and again to produce apparently enormous results, while failed experimental setups will be frequently changed. Sensory leakage could be quite conclusively ruled out in a sufficiently vetted physical setup examined by independent quality auditors.
Fraud is naturally an unpleasant suggestion, for both the innocent and the guilty. The usual rebuttal to this possibility is that fraudsters must be too rare to matter much. But the surveys and audit estimates of fraud rates above suggest the baseline is not very rare. If 5% or 10% of psychologists in general have committed fraud, parapsychologists are disproportionately selected for fraud, and we restrict ourselves to experiments with low analysis freedom and large sample sizes (where p-hacking is hard) we might quickly reach quite high rates.
Now, there is uncertainty about how high baseline fraud rates are, about selection for frauds by field, and selection for fraud by experiment type in null fields. These are testable empirical hypotheses, and parapsychologists I have spoken to have argued that in fact parapsychologists are much more honest and rigorous in their methods than conventional scientists. But I think the hypothesis of high fraud rates when we zoom into the relevant area deserves nontrivial credence, before updating on the evidence for parapsychology being a null field. So to convince me that parpasychology is right I would need strong evidence against the fraud hypothesis, like repeated large highly scrutinized replications by independent skeptical researchers, evidence sufficient to make a high fraud rate (or other systematic error) more incredible than psychic powers.
Are parapsychologists more or less at risk for fraud than regular scientists?
If parapsychologists are much more strongly selected for or encouraged to commit fraud than scientists in other disciplines, than we might believe that fraud is a major problem for the most robust-seeming results in parapsychology, but not in other fields. But if the risk levels are not too far apart, then this may support a new angle for scrutinizing other academic fields.
I have encountered a number of arguments from parapsychologists that they are more trustworthy than other scientists, including:
- Parapsychology studies declare that they are double-blind more often than other fields (true for many fields, to my understanding)
- Parapsychologists and their journals publish more negative results than most fields (again, true)
- Parapsychology is a small field and everyone knows each other, so fraud would be easily detected
- Parapsychologists are under more scrutiny than other scientists, so would be too afraid to cheat
- There's very little money in parapsychology, so fraudsters would do something more profitable instead
- Only a few frauds have been caught among scientific parapsychologists, as opposed to people claiming psychic powers
My own best guess is that fraud risk is as great or greater than in other fields. Kennedy (2014) summarizes evidence on numerous cases of documented fraud and unconfirmed accusations in parapsychology, and a number of structural factors also push this way:
- The view that some experimenters have the 'knack' for success enables the assortment of frauds into positions enabling fraud while other parapsychologists perform other tasks (see Kennedy, 2014)
- The number of frauds reported in Kennedy's article is quite high on a per capita basis if the field has had only a few hundred serious researchers, and the survey and audit data above suggest that frauds are vastly less likely to be caught than to go unpunished
- Belief in experimenter effects provides an all-purpose excuse to deflect fraud accusations
- A single parapsychology laboratory, the Rhine Institute, reported numerous cases of misconduct (without publicly naming the individuals) as a problem under control shortly before its appointed Director (subsidiary to Rhine), W.J. Levy, was also found to have engaged in fraud; this suggests that it may have been unusual not so much in a shocking frequency of frauds but in being willing to report such cases at all (Kennedy, 2014)
- Scarcity of positions and funds, which are provided primarily by psychic believers who may chase positive results, gives a strong financial incentive for fraud among professional parapsychologists (who cannot easily move to another academic field like conventional psychology), once they are in the field for whatever initial reasons, including initial belief
- Parapsychologists are overwhelmingly believers, with those who change their views leaving the field, and active skeptical critics of parapsychology are scarce and devote few person-hours to critique
- Parapsychology positions appear to be less available than conventional psychology ones
- Parapsychologists argue that they are the subject of taboo and persecution, and may especially fear to lend ammunition to their opponents or damage their tight-knit community through investigations and accusations of fraud
Kennedy's article seems to me to offer potent evidence against the view that parapsychology is much less fraud-prone than other fields, but does not resolve the question of whether the situation is very much worse in psychology than in other fields. Eventually, I would hope that practices such as frequent replication, auditing, contract laboratories, pre-registration, high study power, and data sharing become common enough for fraud to clearly stand out. But in the meantime I retain a nagging worry that parapsychology is a warning that we should take fraud more seriously elsewhere when evaluating sparse evidence bases.
Here are better screen shots: 1 2.
ReplyDeleteHi,
ReplyDeleteI have a few questions about the reasons that you think that parapsychology is more prone to fraud:
"The number of frauds reported in Kennedy's article is quite high on a per capita basis if the field has had only a few hundred serious researchers"
Would you happen to know what the fraud rate per capita is in the other fields (both conventional psych and other sciences)?
"A single parapsychology laboratory, the Rhine Institute, reported numerous cases of misconduct (without publicly naming the individuals) as a problem under control shortly before its appointed Director (subsidiary to Rhine), W.J. Levy, was also found to have engaged in fraud; this suggests that it may have been unusual not so much in a shocking frequency of frauds but in being willing to report such cases at all (Kennedy, 2014)"
Is the point here that parapsychologists are less willing to make accusations about fraud, which seems to tie into your last point?
"Parapsychology positions appear to be less available than conventional psychology ones"
Would this be simply due to the fact that parapsychology positions are rarer due to parapsychology research itself being rarer, or is there data to suggest that the ratio of positions to parapsychologists is much lower than in other fields' position to researcher ratios?
The other points seem solid. Thanks.
"Would you happen to know what the fraud rate per capita is in the other fields (both conventional psych and other sciences)?"
ReplyDeleteI linked above to a series of studies for conservative estimates of fraud, and evidence that they are indeed too conservative.
"Is the point here that parapsychologists are less willing to make accusations about fraud, which seems to tie into your last point?"
The Rhine Institute, the flagship parapsychology institution of its time, was rife with fraud (with the mentioned cases said to be only a selected subset of fraud cases) with the frauds not being named and shamed. If that is representative of the field, then the base rate of fraud is enough to explain any sexy results that cannot be replicated reliably by other researchers, or by outsiders.
One might argue that the Rhine could have been exceptional in two ways: it could have been more corrupt than the rest of the field, or it could have been more forthright in exposing corruption.
The "more corrupt" story suffers because of the sheer number of fraud cases. If frauds were randomly distributed, it would be very surprising that so many appeared at that one institution if the base rate is low. That leaves the options that the Rhine Institute differentially attracted or encouraged fraud, and that it was more forthright than usual in exposing it.
The fact that numerous cases for fraud were sat on for decades, until referenced as part of an unusual article towards the end of the lab's history (which might just as well not have been published), and the structure of the laboratory (whereby Rhine was in a position to fire frauds beneath him like Levy, as opposed to many small laboratories which could be run by individual frauds) suggest that Rhine was more unusual in the revelations than fraud prevalence.
"data to suggest that the ratio of positions to parapsychologists is much lower than in other fields' position to researcher ratios?"
This is based on parapsychologists claiming as much, and the membership of their professional societies vs full-time positions.
I see. Thanks for the clarification.
ReplyDelete